Search K
Appearance
单例模式是一种属于对象创建型的模式,即保证系统中类只生成一个对象。这个是一个十分常用的设计模式,比如系统中只初始化一次的资源,如 socket、log 日志文件等,能被多个线程访问,保证其有唯一 1 个实列存在,作为全局变量供其他地方访问,同时也避免重复资源被初始化操作带来错误。简而言之,就是对一个一次性资源的封装,避免被重复申请或初始化,然后作为一个全局变量被访问。
单例模式有如下几个特点:1.确保该资源只被申请或初始化一次 2.定义静态对象指针 3.提供一个函数,全局访问
单例模式又分为懒汉模式和饿汉模式,这两个模式的区别主要在于创建对象方式不一样。
饿汉模式 :定义静态对象指针时候就为它分配资源,由于语言特性限制,在 C++、Java 等语言中可以实现饿汉模式,但在 C 语言中不能实现。所以只能实现下述懒汉单例模式。
//singleton.h
//定义对象进行封装
typedef struct Singleton{
//....
}Singleton;
//创建静态对象指针
//创建对象,在C中此处不能实现,不能在外面直接调用函数创建对象
static Singleton* obj = 构造函数();
//定义函数返回对象指针,供外部程序使用
Singleton* get_inst(void)
{
return obj;
}懒汉模式 : 与饿汉模式对比,即调用 get_inst()时候判断是否创建创建对象。如果未创建,就创建对象。区别就在此,其他的基本上都一样。
//singleton.h
//定义对象进行封装
typedef struct Singleton{
//....
}Singleton;
//创建静态对象指针
static Singleton* obj = NULL;
//定义函数返回对象指针,供外部程序使用
Singleton* get_inst(void)
{
if(obj==NULL){
//C语言中只能在函数内部调用创建对象
obj = 构造函数(); //创建对象
}
return obj;
}懒汉单例模式存在多线程竞争问题,当线程 A 调用 get_inst()时候,若第一次调用,obj 还未申请资源,便会调用构造函数创建,而此时线程 B 也调用 get_inst()时,若构造函数内部创建时间长,此时 obj 还是空,因此线程 B 也会调用构造函数创建对象,此时系统调用了两次构造函数(例如 socket 等创建了两次),不满足逻辑设计,因此需要考虑线程竞争。
**第一种解决方案:**直接加锁,如下示例,锁放在判断条件外,这种方式每次调用 get_inst()都存在加锁解锁,频繁的锁操作增加资源开销,降低了效率;锁放在判断条件内,存在竞争并发问题,几个线程第一次调用 get_inst(),第一次都会判断为空,都会进入 if 条件了,这种时候即使加锁,也没有用了,都会多次创建对象,只是创建对象的先后时间不同,造成内存泄漏,逻辑不正确。
//锁放在判断之外
Singleton* get_inst(void)
{
pthread_mutex_lock(&mutex);
if(obj==NULL){
obj = 构造函数(); //创建对象
}
pthread_mutex_lock(&mutex);
return obj;
}
//锁放在判断内
Singleton* get_inst(void)
{
if(obj==NULL){
pthread_mutex_lock(&mutex);
obj = 构造函数(); //创建对象
pthread_mutex_lock(&mutex);
}
return obj;
}**第二种解决方案:**双检锁,即两次判断,再加锁。第一次判断若未空,再进去加锁,再为空,才创建对象。本篇中采用这种设计。
Singleton* get_inst(void)
{
if(obj==NULL){
pthread_mutex_lock(&mutex);
if(obj==NULL) {
obj = 构造函数(); //创建对象
}
pthread_mutex_lock(&mutex);
}
return obj;
}接下来我们将通过一个例子来实现懒汉单例模式,以平时开发中经常使用到的日志文件为例,一个程序系统中,会存在一个日志操作,通过记录程序的运行状态,方便我们根据日志文件进行程序 bug 的分析。定义一个 log 日志对象,实现不同等级的日志记录,并且保证系统中存在唯一一个 log 日志对象。外部程序通过 log_get_inst()进行访问操作 log 对象。
typedef struct log_t //定义日志对象
{
int (*debug)(const char *__restrict __fmt, ...);
int (*warning)(const char *__restrict __fmt, ...);
int (*error)(const char *__restrict __fmt, ...);
void (*destroy)();
int log_size; //日志文件大小,超过这个值重新创建一个新文件
char log_name[128]; //日志文件名字
FILE *wfile; //文件操作符
}log_t;
static log_t* singleton_log = NULL; //定义的静态对象指针
log_t* log_get_inst(void); //通过对外访问的函数构造函数:通过静态变量 inst_times 控制 log 只被调用一次,并且再.c 文件中使用 static 修改函数,不能被外部调用。
static log_t* construct_singleton_log(int size, const char* filename)
{
static int inst_times=0; //设置一个变量,确保只创建唯一log对象
if(inst_times!=0 || !filename || size<=0) return NULL;
log_t* obj = (log_t*)malloc(sizeof(log_t));
if(!obj) return NULL;
memset(obj, 0, sizeof(obj));
//创建日志文件
if(_open_file(obj)==-1) return NULL;
obj->log_size = size;
obj->debug = log_debug; //给指针函数赋值
obj->warning = log_warning;
obj->error = log_error;
obj->destroy = log_destroy;
inst_times++;
return obj;
}提供对外的访问接口:提供宏定义 _REENTRANT 判断程序是否使用多线程,决定是否加锁。通过双检锁机制保证线程安全。
/**
* @brief: 懒汉单例模式, 供外部调用访问
* @return: 返回一个单例对象
*/
log_t* log_get_inst (void)
{
if(!singleton_log){ //双检锁
#ifdef _REENTRANT //是否使用多线程
pthread_mutex_lock(&log_mutex);
#endif
if(!singleton_log){
singleton_log = construct_singleton_log(LOG_FILE_SIZE, LOG_FILE_NAME);
}
#ifdef _REENTRANT //是否使用多线程
pthread_mutex_unlock(&log_mutex);
#endif
}
return singleton_log;
}接下来时 log 日志文件功能函数的实现:buffer 即传入要写入日志文件的内容,通过静态变量 is_check 控制每 16 次检测日志文件是否达到设定最大值,是否创建新的日志文件,根据系统时间来创建日志的文件名字,这样当系统磁盘空间不足时候,可以根据时间手动去删除以前的日志。
/**
* @brief: 将日志内容写入文件
* @buffer: 日志内容
* @return: 0:ok -1:err
*/
static int _write_file(const char* buffer)
{
static unsigned char is_check=1;
struct stat log_fsta;
size_t ret=0;
if(!buffer || !singleton_log) return -1;
#ifdef _REENTRANT //是否使用多线程
pthread_mutex_lock(&log_mutex);
#endif
ret = fwrite(buffer, 1, strlen(buffer), singleton_log->wfile);
// if( (++is_check) % 16 != 0 ) goto exit; //写入16次检测一次是否要将日志写入另外一个文件
if( ((++is_check)&0xF) != 0 ) goto exit; //写入16次检测一次是否要将日志写入另外一个文件
fflush(singleton_log->wfile);
stat( singleton_log->log_name, &log_fsta ); //获取文件的大小
if( log_fsta.st_size > singleton_log->log_size ){ //写到设定值,重新打开一个文件写入
fclose( singleton_log->wfile ); //关闭当前文件
_open_file(singleton_log); //创建一个新文件
}
exit:
#ifdef _REENTRANT //是否使用多线程
pthread_mutex_unlock(&log_mutex);
#endif
return ret;
}函数 debug、warning、error 不同等级的记录,实现几乎一样的,下面以 debug 为例:先对当前记录的时间、文件名字、行号格式化到 buffer 以后,再将其他信息格式化到 buffer,这样记录的信息就比较多,便于分析。
/**
* @brief: log记录debug的日志信息
* @input: 传入可变参数
* @note: 采用static修饰,外部其他文件不能直接调用,
* 赋值给函数指针,通过函数指针进行调用
* @return: 0:ok -1:err
*/
static int log_debug(const char *__restrict __fmt, ...)
{
va_list args;
time_t rawtime;
struct tm *tminfo=NULL;
int size=0, ret = 0;
char buffer[1024], time_buf[128];
if(!singleton_log) return -1;
time(&rawtime);
tminfo = localtime(&rawtime);
// strftime(time_buf, sizeof(time_buf), "%Y-%m-%d %H:%M:%S", tminfo);
size = sprintf(buffer, "[debug]: Time:%d-%d-%d %d:%d:%d File:%s Line:%d @: ",
tminfo->tm_year+1900, tminfo->tm_mon+1, tminfo->tm_mday, \
tminfo->tm_hour, tminfo->tm_min, tminfo->tm_sec, __FILE__, __LINE__);
va_start(args, __fmt); //定义可变参数列表
size = vsnprintf(buffer+size, 1024-size, __fmt, args); //buffer+size是偏移前面固定信息,避免被覆盖
va_end(args);
return _write_file(buffer);
}测试函数如下:包含单例模式,直接调用debug、warning、error等记录日志信息。采用多线程测试,创建两个线程,都往同一个日志文件中写数据,当日志文件大小超过宏定义设置的大小时候,会根据系统时间创建新的日志文件。
#include "singleton.h"
#include <pthread.h>
void* task1(void *args)
{
int i=0;
for(i=0; i<100; i++){
log_get_inst()->debug("task1 i=%d....\n", i);
log_get_inst()->warning("task1 i=%d....\n", i);
log_get_inst()->error("task1 i=%d....\n", i);
usleep(500000);
}
}
void* task2(void *args)
{
int i=0;
for(i=0; i<100; i++){
log_get_inst()->debug("task2 i=%d....\n", i);
log_get_inst()->warning("task2 i=%d....\n", i);
log_get_inst()->error("task2 i=%d....\n", i);
usleep(500000);
}
}
int main(int argc, char **argv)
{
pthread_t th1, th2;
pthread_create(&th1, NULL, task1, NULL);
pthread_create(&th2, NULL, task2, NULL);
pthread_join(th1, NULL);
pthread_join(th2, NULL);
log_get_inst()->destroy();
return 0;
}运行生成几个日志文件,实际使用中可以把文件阈值设置大一点,此处作为测试设置10k左右

日志文件中的内容:有不同等级的日志信息,也有不同线程写入的日志信息。
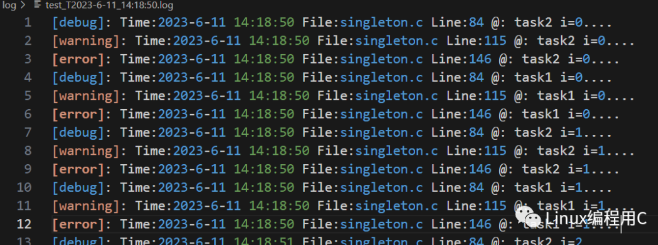
工程使用:
工程目录:log目录存放日志文件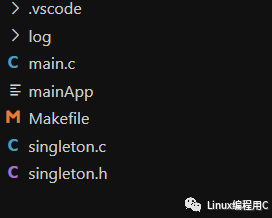
再Linux平台下,输入make进行编译,输入make clean清除编译中间文件。mainApp是可执行文件。
在singleton.h文件有两个宏的定义,设置日志文件大小,即日志文件名字前缀。
#define LOG_FILE_SIZE (10*1024U)
#define LOG_FILE_NAME "./log/test"虽然C语言是面向过程的编程语言,但是我们在设计程序的时候,可以考虑用面向对象的方式去设计,这样提高我们程序的“高内聚、低耦合”特性,便于维护。
建造者模式: 也称生成器模式,是 23 种设计模式中的一种,是一种创建型模式。适用情况:一个对象比较复杂,将一个对象的构建和对象的表示进行分离。
比较:与工厂模式进行对比,工厂模式不考虑对象部件组装过程,直接生成一个最终的对象,强调的是 *结果* 。而建造者模式先构建对象的每一个部件,然后再统一组建成一个对象,强调的是 过程。
目的:实现复杂对象的生产流程与部件进行解耦。
以建造房子为例,房子有公寓、别墅、楼房等类型,虽然是不同种类的房子,但其建造过程大体上都相同,例如都有这些流程:修建墙、窗户、门、地板、楼顶等。
我们实现 Builder(建造者)建房,因为都有修建(墙、窗户、门、楼等)这些部件,但是具体实现却不同,所以我们需要把实现这些组建的操作给抽象出来,把每个部件实现了,然后再组装起来,修建的房子就完成了。
设计建造者抽象接口如下通过指针函数与结构体进行抽象
typedef struct IBuilder_t //建造者抽象接口
{
void (*make_floor)(void *obj); //修建地板
void (*make_door)(void *obj); //修建门
void (*make_wall)(void *obj); //修建墙
void (*make_window)(void *obj); //修建窗
void (*destory)(void *obj); //释放内存
House_t *house; //house对象
}IBuilder_t;定义房子对象,然后房子里面的部件(墙、窗、门、地板等)交给建造者设置修建。
typedef struct House_t //定义房子要实现的接口
{
void (*setfloor)(struct House_t* obj, char *floor);
void (*setdoor)(struct House_t* obj, char *door);
void (*setwall)(struct House_t* obj, char *wall);
void (*setwindow)(struct House_t* obj, char *window);
char floor[32]; //地板名字
char door[32]; //门名字
char wall[32]; //墙名字
char window[32]; //窗名字
}House_t;
//修建的地板类型。
//static修饰,不让外部直接调用这个函数,
//一般这些函数的实现放到.c文件中,结构体定义在.h文件中,
//而是通过House_t结构体的setfloor()函数指针进行调用,起到封装效果(下同)。
static void house_setfloor(House_t* obj, char *floor)
{
if(obj) sprintf(obj->floor, "%s", floor);
}
//修建的门类型
static void house_setdoor(House_t* obj, char *door)
{
if(obj) sprintf(obj->door, "%s", door);
}
//修建的墙类型
static void house_setwall(House_t* obj, char *wall)
{
if(obj) sprintf(obj->wall, "%s", wall);
}
//修建的窗类型
static void house_setwindow(House_t* obj, char *window)
{
if(obj) sprintf(obj->window, "%s", window);
}
//构造函数 创建一个房子的对象
//此处这个函数不能适用static修饰
//该函数是要开放被外部调用的
House_t* constructor_house(void)
{
House_t* house = (House_t*)malloc(sizeof(House_t)); //申请对象
house->setdoor = house_setdoor; //函数指针赋值
house->setfloor = house_setfloor; //函数指针赋值
house->setwall = house_setwall; //函数指针赋值
house->setwindow = house_setwindow;//函数指针赋值
return house; //返回一个房子对象
}接下来我们实现 builder,修建一个公寓。注:另外一个修建别墅实现,与修建公寓实现几乎完全一致,此处不做过多阐述。
//建造公寓的结构体,与IBuilder_t定义一致,即对IBuilder_t的实现
typedef struct FlatBuilder_t
{
void (*make_floor)(void *obj);
void (*make_door)(void *obj);
void (*make_wall)(void *obj);
void (*make_window)(void *obj);
void (*destory)(void *obj);
House_t *house;
}FlatBuilder_t;
//建造地板。static修饰作用同上
static void flat_make_floor(void *obj)
{
FlatBuilder_t* flat = (FlatBuilder_t*)obj;
flat->house->setfloor(flat->house, "修建:flat floor");
}
//建造门
static void flat_make_door(void *obj)
{
FlatBuilder_t* flat = (FlatBuilder_t*)obj;
flat->house->setdoor(flat->house, "修建:flat door");
}
//建造墙
static void flat_make_wall(void *obj)
{
FlatBuilder_t* flat = (FlatBuilder_t*)obj;
flat->house->setwall(flat->house, "修建:flat wall");
}
//建造窗
static void flat_make_window(void *obj)
{
FlatBuilder_t* flat = (FlatBuilder_t*)obj;
flat->house->setwindow(flat->house, "修建:flat window");
}
//释放内存的函数
static void flat_destory(void *obj)
{
FlatBuilder_t* flat = (FlatBuilder_t*)obj;
if(flat->house) free(flat->house); //首先先释放flat包含的house内存
flat->house=NULL;
free(flat); //其次再释放当前对象
flat=NULL;
}
//公寓建造者的构造函数,此处不能采用static修饰,因为其要被外部调用
FlatBuilder_t* constructor_flat_builder(void)
{
FlatBuilder_t* flat = (FlatBuilder_t*)malloc(sizeof(FlatBuilder_t));
flat->house = constructor_house();
flat->make_door = flat_make_door;
flat->make_floor = flat_make_floor;
flat->make_wall = flat_make_wall;
flat->make_window = flat_make_window;
flat->destory = flat_destory;
return flat;
}main 函数里面的测试代码如下:定义一个 IBuilder_t *buidler=NULL,用它指向不同的建造者,实现修建不同的房子。此时修建公寓和别墅两种不同房子。
int main(void)
{
House_t *house=NULL;
IBuilder_t *buidler=NULL;
//指向公寓建造者,修建公寓
buidler=(IBuilder_t*)constructor_flat_builder();
buidler->make_door(buidler); //修建公寓的门
buidler->make_floor(buidler); //修建公寓的地板
buidler->make_wall(buidler); //修建公寓的墙
buidler->make_window(buidler);//修建公寓的窗
house = buidler->house; //拿到修建的好的房子
printf("%s\n", house->door); //显示公寓门
printf("%s\n", house->floor); //显示公寓地板
printf("%s\n", house->wall); //显示公寓墙
printf("%s\n", house->window);//显示公寓窗
buidler->destory(buidler); //释放内存
printf("\n");
//指向别墅建造者,修建别墅
buidler=(IBuilder_t*)constructor_villa_builder();
buidler->make_door(buidler); //修建别墅的门
buidler->make_floor(buidler); //修建别墅的地板
buidler->make_wall(buidler); //修建别墅的墙
buidler->make_window(buidler); //修建别墅的窗
house = buidler->house; //拿到修建好的房子
printf("%s\n", house->door); //显示别墅门
printf("%s\n", house->floor); //显示别墅地板
printf("%s\n", house->wall); //显示别墅墙
printf("%s\n", house->window); //显示别墅窗
buidler->destory(buidler); //释放内存
return 0;
}执行的效果如下图:

通过上面的内容,我们了解到建造者模式主要是针对创建对象的过程的,而且还可以控制一个复杂类中部件创建的顺序以及部件创建的内容。提高程序的扩展性,践行“高内聚、低耦合”。
1.原型模式 prototype,是一种 创建型模式 ,它采用复制原型对象的方法来创建对象的实例,具有与原型一样的数据。
2.原型对象自身创建一个目标对象,通过 prototype 模式创建的对象与原始对象具有相同的数值。即拷贝原始对象的数据。
3.主要解决的是:"某些结构复杂的对象"的创建工作,由于需求的变化,但是他们都拥有比较稳定统一的接口。一个复杂对象,具有自我复制的功能,统一一套接口。例如:资源优化场景,一个模块(对象)的初始化需要消耗很大资源,这个资源包括数据、硬件等资源等,然后我们通过拷贝并修改特定的数据来减少重复初始化对象所消耗的资源与时间。
1.设计思路设计一个抽象接口结构体(struct Interface_t),包含一些统一接口,然后设计一个 student 结构体,实现抽象结构体定义的接口。
2.接口定义
//定义抽象接口结构体
typedef struct Interface_t
{
//clone()函数指针
struct Interface_t*(*clone)(void *obj);
//设置数据的set()的函数指针
void (*set)(void* obj, const char* name, int age);
//显示信息show()的函数指针
void (*show)(void* obj);
//定义的数据
char name[32];
int age;
}Interface_t;实现 student 结构体的定义
//定义student结构体,与抽象结构体接口一致
typedef struct Student_t
{
//定义clone函数指针
struct Interface_t*(*clone)(void *obj);
//定义set函数指针
void (*set)(void* obj, const char* str, int age);
//定义show函数指针
void (*show)(void* obj);
//定义数据
char name[32];
int age;
}Student_t;
/**
* 简介: set函数的具体实现,修改数据的
* 参数: obj传入当前student结构体,str即要修改的名字,age即修改的年龄
* 返回值: 无
* 其他:使用static修饰,避免被外部直接调用,但可以通过结构体指针进行调用。
*/
static void student_set(void* obj, const char* str, int age)
{
if(!obj || !str) return;
Student_t* s = (Student_t*)obj;
strcpy(s->name, str); //修改student名字
s->age = age; //修改student年龄
}
/**
* 简介: 显示student信息
*/
static void student_show(void *obj)
{
Student_t *s = (Student_t*)obj;
printf("显示 学生信息: 姓名[%s] 年龄[%d]\n", s->name, s->age);
}
/**
* 简介: 重要,克隆student对象的数据信息
* 参数: obj即传入当前的student结构体信息
* 返回值:返回克隆的Interface,其已具有student的信息。
* 其他:具有与student相同的数据与接口。
*/
static Interface_t* student_clone(void *obj)
{
Interface_t *iobj = (Interface_t*)malloc(sizeof(Interface_t));
Student_t* s = (Student_t*)obj;
if(!iobj) return NULL;
iobj->show = student_show;
iobj->set = student_set;
iobj->clone = student_clone;
strcpy(iobj->name, s->name);
iobj->age = s->age;
printf("调用clone()函数, clone Student\n");
return iobj;
}
/**
* 简介: student的构造函数,创建一个student对象
* 参数:无
* 返回值:student对象
* 其他:外部调用该函数构造一个student对象
*/
Student_t* constructor_student(void)
{
Student_t* s = (Student_t*)malloc(sizeof(Student_t));
s->clone = student_clone;
s->set = student_set;
s->show = student_show;
return s;
}1.测试思路先使用构造函数创建一个 student 对象,调用 set()函数设置值并打印信息。然后使用 student 的 clone()函数克隆一个相同数据的对象赋值给 Interface 统一接口,直接打印信息,此时打印的信息与原始对象即 student 的信息一样的,因为其是克隆来的。最后调用 Interface 的 set 函数修改数据,再次打印显示。
2.测试程序
int main(void)
{
printf("原始的学生信息: \n");
Student_t *s1 = constructor_student();
s1->set(s1, "张三", 32);
s1->show(s1);
printf("\n");
Interface_t* i1 = s1->clone(s1);
free(s1);
printf("调用clone(),拷贝后的信息: \n");
i1->show(i1);
printf("\n");
printf("重新修改信息: ");
i1->set(i1, "李四", 41);
i1->show(i1);
free(i1);
return 0;
}3.测试结果与预期一致。
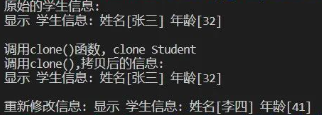
虽然C语言是面向过程的编程语言,但是我们在设计程序的时候,可以考虑用面向对象的方式去设计,这样提高我们程序的“高内聚、低耦合”特性,便于维护。
1.代理模式,是构造型的设计模式之一,是一个使用率比较高的模式,它可以为其他对象提供一种代理(Proxy)以控制对这个对象的访问。
2.所谓代理,是指具有与代理元(被代理的对象)具有相同的接口的类,客户端必须通过代理与被代理的目标类交互,而代理一般在交互的过程中(交互前后),进行某些特别的处理。
3.代理模式也叫做委托模式,在日常的应用中,代理模式可以提供非常好的访问控制。
4.代理模式的优点: 职责清晰、高扩展性。
5.代理模式的类图如下,我们作为client使用时,直接访问interface这个抽象接口,真实的RealSubject与Proxy代理类继承该interface抽象接口,并实现接口定义函数。
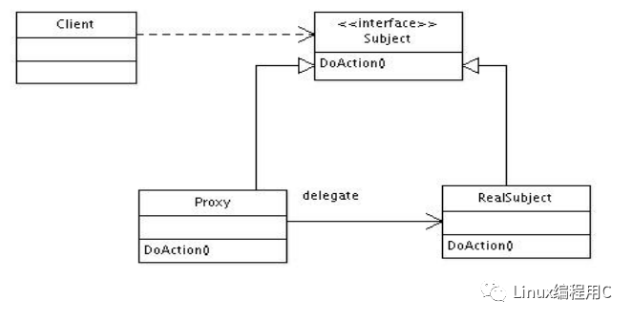
1.设计思路,本设计以服装店卖衣服为例,通过服装店自己卖衣服和淘宝店代理卖衣服对比,感受一下代理模式优点。
2.设计的抽象接口如下。
//定义的代理模式抽象接口
typedef struct IProxy_t
{
void (*sale)(void *obj); //卖衣服接口
void (*discount)(void *obj, float discount_num); //打折接口
void (*free)(void *obj); //最后释放内存
}IProxy_t;3.服装店相关定义的实现
//服装店结构体
//注: 前面三个函数接口顺序与IProxy_t定义的要一致。
typedef struct ClotheStore_t
{
void (*sale)(void *obj); //卖衣服函数
void (*discount)(void *obj, float discount_num);//打折函数
void (*free)(void *obj); //释放内存
float price; //服装价格
}ClotheStore_t;
/**
* 简介:实现释放内存接口
* 参数:传入当前的服装店结构体
* 返回值:无
*/
static void clothe_store_free(void *obj)
{
ClotheStore_t *csobj = (ClotheStore_t*)obj;
if(csobj) free(csobj);
}
/**
* 简介:实现卖衣服函数接口
* 参数:传入当前的服装店结构体
* 返回值:无
*/
static void clothe_store_sale(void *obj)
{
ClotheStore_t *csobj = (ClotheStore_t*)obj;
printf("服装店: 卖衣服! 价格是: %.2f元\n", ((ClotheStore_t*)obj)->price);
}
/**
* 简介:实现打折计算函数接口
* 参数:传入当前的服装店结构体、 打折值
* 返回值:无
*/
static void clothe_store_discount(void *obj, float discount_num)
{
printf("服装店: 现在做活动打 %.1f 折, 欢迎选购! \n", discount_num);
ClotheStore_t *cs = (ClotheStore_t*)obj;
cs->price *= discount_num/10.0;
}
/**
* 简介:服装店结构体构造函数
* 参数:无
* 返回值:创建的服装店对象
*/
ClotheStore_t* constructor_clothe_store(void)
{
ClotheStore_t* obj = (ClotheStore_t*)malloc(sizeof(ClotheStore_t)); //申请内存
obj->price = 588; //数据成员赋值
obj->discount = clothe_store_discount; //函数指针赋值,便于后续调用,下同
obj->sale = clothe_store_sale;
obj->free = clothe_store_free;
return obj;
}4.淘宝代理接口定义及实现如下。
//定义淘宝代理结构体
//注:前3个函数指针与IProxy_t定义一致,方便后续发生“多态”作用
//即动态选择函数执行
typedef struct ProxyTaoBao_t
{
void (*sale)(void *obj); //淘宝卖衣服
void (*discount)(void *obj, float discount_num);//打折
void (*free)(void *obj); //释放资源
void (*before)(void *obj); //售前
void (*after)(void *obj); //售后
ClotheStore_t *csobj; //给服装店做代理
}ProxyTaoBao_t;
/**
* 简介: 实现淘宝代理卖衣服函数接口
* 参数:传入当前调用的结构体
* 返回值: 无
* 其他: 代理服装店卖衣服,实际上真正卖衣服还是服务站
* 不过由淘宝代理,增加一些售前、售后服务等
*/
static void taobao_sale(void *obj)
{
ProxyTaoBao_t *tbobj = (ProxyTaoBao_t*)obj;
tbobj->before(tbobj); //做售前工作
tbobj->discount(tbobj, 9.5); //淘宝做活动打折9.5折
tbobj->csobj->discount(tbobj->csobj, 9.8); //商家打折9.8折
tbobj->csobj->sale(tbobj->csobj); //实际卖衣服还是服装商家
tbobj->after(tbobj); //做售后工作
}
/**
* 简介: 实现淘宝代理打折函数接口
* 参数:传入当前调用的结构体、打折值
* 返回值: 无
*/
static void taobao_discount(void *obj, float discount_num)
{
ProxyTaoBao_t *tbobj = (ProxyTaoBao_t*)obj;
tbobj->csobj->price *= discount_num/10.0;
printf("淘宝做活动, 全场打 %.1f 折! 欢迎选购!!!\n", discount_num);
}
/**
* 简介: 实现淘宝代理售前函数接口
* 参数:传入当前调用的结构体
* 返回值: 无
*/
static void taobao_before(void *obj)
{
printf("淘宝售前: 亲!欢迎咨询...\n");
}
/**
* 简介: 实现淘宝代理售后函数接口
* 参数:传入当前调用的结构体
* 返回值: 无
*/
static void taobao_after(void *obj)
{
printf("淘宝售后: 亲!有问题请联系我哦...\n");
}
/**
* 简介: 实现淘宝代理free函数接口
* 参数:传入当前调用的结构体
* 返回值: 无
*/
static void taobao_free(void *obj)
{
ProxyTaoBao_t* tbobj = (ProxyTaoBao_t*)obj;
if(tbobj->csobj) free(tbobj->csobj);
if(tbobj) free(tbobj); //释放资源
}
/**
* 简介: 淘宝代理构造函数,申请对象资源,初始化等
* 参数:无
* 返回值: 淘宝代理对象结构体指针
*/
ProxyTaoBao_t* constructor_proxy_taobao(void)
{
ProxyTaoBao_t* obj = (ProxyTaoBao_t*)malloc(sizeof(ProxyTaoBao_t));//申请内存
obj->after = taobao_after; //赋值函数指针,便于后续指针调用
obj->before = taobao_before; //赋值函数指针,便于后续指针调用,下同
obj->csobj = constructor_clothe_store(); //创建实体店对象
obj->discount = taobao_discount;
obj->free = taobao_free;
obj->sale = taobao_sale;
return obj;
}我们来测试对比一下服装店直接卖衣服和淘宝店代理卖衣服的区别,测试程序如下:
int main(void)
{
IProxy_t *obj = NULL;
printf("------------------------------\n");
printf("普通实体店卖衣服:\n");
ClotheStore_t *csobj = constructor_clothe_store();
obj = (IProxy_t*)csobj;
obj->discount(obj, 9.8);
obj->sale(obj);
obj->free(obj);
printf("\n------------------------------\n");
printf("淘宝代理卖衣服: \n");
ProxyTaoBao_t *tbobj = constructor_proxy_taobao();
obj = (IProxy_t*)tbobj;
obj->sale(obj);
obj->free(obj);
return 0;
}测试结果:

1.通过上面的测试结果,我们可以了解到,真正干活的还是服装店,不过加上代理模式后,整个销售流程更加完善,功能更加丰富。实际开放中,代理模式可以较小程度的修改原有程序来实现增加新的功能。
2.虽然C语言是面向过程的编程语言,但是我们在设计程序的时候,可以考虑用面向对象的方式去设计,这样提高我们程序的“高内聚、低耦合”特性,便于维护。
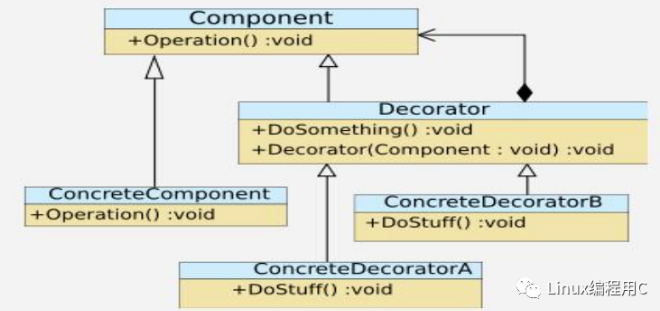
本篇小C将带领大家来了解学习装饰模式,该模式也是日常开放中使用较多的模式。 1. 装饰(Decorator)模式:又叫做包装模式。通过一种对客户端透明的方式来扩展对象的功能,是继承关系的一个替换方案。 2. 装饰模式就是把要添加的附加功能分别放在单独的类中,并让这个类包含它要装饰的对象,当需要执行时,客户端就可以有选择地、按顺序地使用装饰功能包装对象。 3.装饰模式的使用场景 需要扩展一个类的功能,或给一个类增加一个附加的功能;需要动态地给一个对象增加功能。 4.UML类图
装饰类通过对抽象组件的继承,实现具体装饰类A、具体装饰类B,具体组件类,可动态装饰实现增加新的功能。
1.本篇中以车为例子,由一个普通的小汽车一层一层的装饰,实现一个超级房车(可越野、可竞速等)。 2.首先定义一个交通工具抽象接口:两个函数指针,run() 实现汽车的功能,free() 最后释放内存资源。
//定义的抽象交通工具接口
typedef struct vehicle_t
{
void (*run)(void *obj);//实现汽车的功能
void (*free)(void *obj);//释放资源
}vehicle_t;先阐述一个概念: "继承" vehicle_t实现car_t的相关定义。此处的“继承”并非C++、JAVA中的继承,C语言中没有继承,此处只是引用"继承"的概念,即car_t定义包含vehicle_t的定义,且顺序也相同。但是后面可以加入car_t自己特有的数据定义。这样便于后面发生"多态"的作用,实现设计模式。
//"继承"上面vehicle_t接口实现car
//"继承":C语言中没有继承这个说法,此处引用C++中的继承概念
//需要在car_t结构中保持与vehicle_t定义的结构与顺序实现"继承"。
//只需要保证前面的与定义接口结构与顺序一致,后面可以加入自有的特性
//下同
typedef struct car_t
{
void (*run)(void *obj); //vehicle_t中的定义
void (*free)(void *obj);//vehicle_t中的定义
//car结构特有的定义
vehicle_t *m_veh; //car_t特有的定义
void (*characte)(void *obj); //car_t特有的定义
}car_t;
//实现car的运行函数,采用static修饰,具体作用往期设计模式有说明。
static void car_run(void *obj)
{
if(!obj) return; //判断指针是否有效
car_t *car = (car_t*)obj;
//"发生多态调用",实现装饰模式
if(car->m_veh) car->m_veh->run(car->m_veh);
car->characte(car); //调用自身的特性
}
//car释放内存的函数
static void car_free(void *obj)
{
if(!obj) return;
car_t *car = (car_t*)obj;
if(car->m_veh) free(car->m_veh);
car->m_veh = NULL;
free(car);
car = NULL;
printf("释放 普通车对象 内存!!!\n");
}
//实现car特有的功能函数
static void car_characte(void *obj)
{
printf("功能: 可以跑!!!\n");
}
//实现car的带参"构造函数",创建一个car对象
//传入要装饰的对象,此处以抽象接口作为定义参数
//返回一个car_t的指针
car_t* constuctor_car(vehicle_t* veh)
{
car_t *obj = (car_t*)malloc(sizeof(car_t));
obj->run = car_run;
obj->free = car_free;
obj->characte = car_characte;
obj->m_veh = veh;
return obj;
}实现一个SUV越野车的接口定义。与上面的car_t实现方式基本一致,因为都是对vehicle_t接口的实现,并加上的自身特有的功能。此处限于篇幅原因,另外的赛车与超级房车使用未贴代码,但实现方式与car_t、suvcar_t一致。
typedef struct suvcar_t
{
void (*run)(void *obj);
void (*free)(void *obj);
// SUV Car结构的特性
vehicle_t *m_veh;
void (*characte)(void *obj);
}suvcar_t;
//SUV的功能实现函数
static void suv_run(void *obj)
{
if(!obj) return;
suvcar_t *suv = (suvcar_t*)obj;
if(suv->m_veh) suv->m_veh->run(suv->m_veh);
suv->characte(suv);
}
//释放SUV对象内存资源函数
static void suv_free(void *obj)
{
if(!obj) return;
suvcar_t *suv = (suvcar_t*)obj;
if(suv->m_veh) free(suv->m_veh);
suv->m_veh = NULL;
free(suv);
suv=NULL;
printf("释放 越野车对象 内存!!!\n");
}
//SUV特性函数
static void suv_characte(void *obj)
{
printf("功能: 可以越野!!!\n");
}
//SUV的"构造函数",创建一个SUV对象
suvcar_t* constuctor_suvcar(vehicle_t *veh)
{
if(!veh) return NULL;
suvcar_t *suv = (suvcar_t*)malloc(sizeof(suvcar_t));
suv->run = suv_run;
suv->free = suv_free;
suv->characte = suv_characte;
suv->m_veh = veh;
return suv;
}1.测试思路:先创建一个普通的汽车,通过层层的装饰实现一个可以越野、可以竞速、可以做饭、生活的超级房车。这体现了动态为对象增加功能,最开始是一个功能简单的汽车,通过需求进行装饰,实现更复杂的功能。 2.测试程序: 先创建了普通的car汽车,然后创建越野车suv时候通过对car的修饰(即将car对象传入越野车的构造函数),变成越野车。然后将越野车对象传入竞速车构造函数,创建竞速车,此时竞速车拥有越野车的功能,还有自身竞速功能。最后将竞速车对象传入超级房车的构造函数,测试超级房车拥有越野、竞速、房车的功能。体现了装饰模式动态增加功能,便于扩展新功能特性。
int main(void)
{
vehicle_t *veh=NULL;
printf("\033[1;43;33mC语言实现设计模式-装饰模式!\033[0m\n");
printf("开始装饰 \033[1;42;32m[汽车]\033[0m: \n");
car_t *car = constuctor_car(veh);
car->run(car); //调用汽车的功能
printf("\n开始装饰 \033[1;42;32m[越野车]\033[0m: \n");
//在普通汽车基础上(装饰),增加越野车功能
suvcar_t *suv = constuctor_suvcar((vehicle_t*)car);
suv->run(suv); //拥有普通汽车的功能,再添加上suv的功能
printf("\n开始装饰 \033[1;42;32m[赛车]\033[0m: \n");
//在越野车基础上(装饰),增加赛车功能
racecar_t *race = constuctor_racecar((vehicle_t*)suv);
race->run(race); //拥有越野车、普通车功能,再添加上竞速功能
printf("\n开始装饰 \033[1;42;32m[超级房车]\033[0m: \n");
//在竞速汽车基础上(装饰),增加房车功能
tourcar_t *tour = constuctor_tourcar((vehicle_t*)race);
tour->run(tour); //拥有竞速车、越野车、普通车功能,再添加上房车功能
//printf("\033[显示方式;字背景颜色;字体颜色m 字符串 \033[0m" );
printf("\n\033[1;41;31m 释放资源 \033[0m \n");
tour->free(tour);
race->free(race);
suv->free(suv);
car->free(car);
return 0;
}测试结构与预期一致:
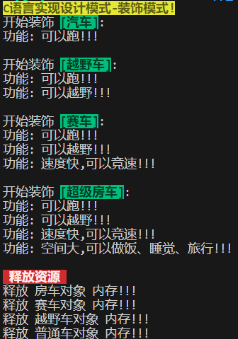
1.通过上面的测试结果,我们可以看到,由最开始的一个普通汽车,通过层层的装饰,动态的增加新功能,实现一个功能丰富的"超级房车"。体现出装饰模式的易扩展性。
2.虽然C语言是面向过程的编程语言,但是我们在设计程序的时候,可以考虑用面向对象的方式去设计,这样提高我们程序的“高内聚、低耦合”特性,便于维护。
1. Adapter模式: 也叫适配器模式,是构造型模式之一,通过 Adapter模式可以改变已有类(或外部类)的接口形式。 **2. 适用于:**是将一个类的接口转换成客户希望的另外一个接口。使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。 3. 优点: 提高代码的复用度、灵活性高 4. UML类图: 目标角色(Target):客户端期望的接口,抽象类或接口 适配者角色(Adaptee):已存在接口,但是和客户端期望的接口不一致 适配器角色(Adaper):适配器,将适配者角色现有的接口进行适配,满足目标角色
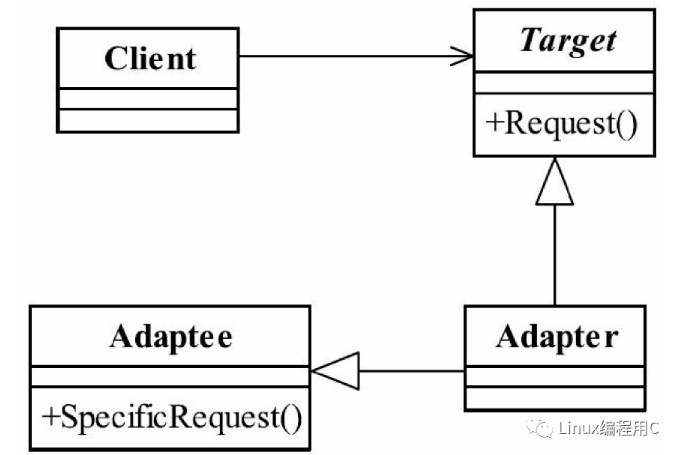
适配器这个概念,我们在生活中是很常见的,比如电源适配器,将市电220V转换为设备所需要的电压;电源三脚插头通过转换变成两脚插头使用等这些都存在适配器的概念。本篇以手机想使用USB接口的U盘为例,手机直接使用不了USB接口的设备,需要将USB接口转换为Type-C的接口,才可以使用。

目标TARGET: 最终客户期望的接口,本例即期望Type-C接口
//目标target,即现在业务需要的对象接口
typedef struct TypeCDisk
{
void (*use_typeC_disk)(void* obj, int len); //使用TYPE-C接口
void (*free)(void* obj);//释放资源
}TypeCDisk;**适配者角色Adaptee:**已存在老的接口,本例即USB接口的U盘
//已经存在的老业务模块
typedef struct USBDisk
{
//使用USB接口的U盘
void (*use_usb_disk)(void* obj, char *color, char *texture, int len);
void (*free)(void *obj);//释放资源
char color[32]; //U盘颜色
char texture[32]; //U盘材质
int wire_len; //U盘线长
}USBDisk;
//使用USB接口U盘
static void use_usb_disk(void* obj, char *color, char *texture, int len)
{
if(!obj || !color || !texture) return;
USBDisk* usb = (USBDisk*)obj;
sprintf(usb->color, "%s", color);
sprintf(usb->texture, "%s", texture);
usb->wire_len = len;
printf("材质:%s 颜色:%s 长度:%dCM USB接口U盘\n",usb->texture,usb->color,usb->wire_len);
}
//释放资源
static void free_usb_disk(void *obj)
{
if(obj) free(obj);
obj=NULL;
}
//USB接口U盘构造函数,创建一个USBDisk对象
USBDisk* constructor_usb_disk(void)
{
USBDisk* usb = (USBDisk*)malloc(sizeof(USBDisk));
usb->use_usb_disk = use_usb_disk;
usb->free = free_usb_disk;
return usb;
}**适配器角色(Adaper):**适配器即转换器,将USB接口转换为Type-C接口的东西
//适配器结构,继承目标target,关联适配者角色Adaptee(即存在老的模块)
typedef struct AdapterDisk
{
void (*use_typeC_disk)(void* obj, int len); //使用Type-C接口的U盘
void (*free)(void* obj); //释放资源
int wire_len;
USBDisk* usb;
}AdapterDisk;
//适配器使用Type-C接口U盘
static void adapter_use_typeC_disk(void* obj, int len)
{
AdapterDisk* disk = (AdapterDisk*)obj;
disk->wire_len = len;
//将USB接口与Type-C接口进行适配
disk->usb->use_usb_disk(disk->usb,"黑色","铝制",len);
}
//释放资源
static void adapter_use_typeC_free(void* obj)
{
if(obj) free(obj);
obj=NULL;
}
//适配器构造带参函数,需要传入适配者角色Adaptee(即存在老的模块)对象
//返回一个适配器对象
AdapterDisk* constructor_adapter_disk(USBDisk* usbdisk)
{
AdapterDisk* disk = (AdapterDisk*)malloc(sizeof(AdapterDisk));
disk->use_typeC_disk = adapter_use_typeC_disk;
disk->free = adapter_use_typeC_free;
disk->usb = usbdisk;
return disk;
}先创建一个适配者角色Adaptee(即存在老的模块)对象,将Adaptee作为参数传入适配器构造函数,创建适配器对象,此时转换提供了Type-C接口,手机便可以使用Type-C接口的U盘。
int main(void)
{
TypeCDisk* typeC=NULL;
printf("1.创建一个USB接口U盘。\n");
USBDisk* usb = constructor_usb_disk();
printf("2.连接适配器。\n");
typeC = (TypeCDisk*)constructor_adapter_disk(usb);
printf("3.已有Type-C接口,接上手机: ");
typeC->use_typeC_disk(typeC, 20);
typeC->free(typeC);
usb->free(usb);
return 0;
}运行结果:与预期一致。

Template Method 模式也叫模板方法模式,是行为模式之一,它把具有特定步骤算法中的某些必要的处理委让给抽象方法,通过子类继承对抽象方法的不同实现改变整个算法的行为。
Template Method 模式一般应用在具有以下条件的应用中:
1.本篇以 CPU 初始化流程为例对模板模式进行说明,例如 CPU 的初始化流程都大致一样,初始化硬盘、外设、内存、网络等,但是每个 CPU 初始化具体的细节却不相同,即初始化流程可以看作一个模板,有统一的操作步骤,但具有不同的操作细节。下面以 Intel CPU 和 AMD CPU 初始化为例。
2.首先定义抽象接口:初始化外设、硬盘、内存、网络等,init()函数即是模板,包含整个初始化流程,即外部调用一个 init()函数即可对 CPU 进行初始化。
typedef struct Interface_t
{
/*初始化外设USB、SPI、IIC等*/
void (*init_peripheral)(void *obj);
/*初始化硬盘*/
void (*init_disk)(void* obj);
/*初始化内存*/
void (*init_memory)(void* obj);
/*初始化网络*/
void (*init_net)(void *obj);
/*对整个流程初始化*/
void (*init)(void *obj);
}Interface_t;3.AMD CPU 初始化相关定义,Intel CPU 相关代码实现与下面的实现几乎一致,此处不再贴代码。
//定义一个Intel CPU初始化结构体
typedef struct AMDCpuStart_t
{
void (*init_peripheral)(void *obj); //初始化外设
void (*init_disk)(void* obj); //初始化硬盘
void (*init_memory)(void* obj); //初始化内存
void (*init_net)(void *obj); //初始化网络
void (*init)(void *obj); //模块 整个初始化流程
}AMDCpuStart_t;
static void ADM_init_peripheral(void *obj)
{
printf("初始化AMD 外设...\n");
}
static void ADM_init_disk(void *obj)
{
printf("初始化AMD 硬盘...\n");
}
static void ADM_init_memory(void *obj)
{
printf("初始化AMD 内存...\n");
}
static void ADM_init_net(void *obj)
{
printf("初始化AMD 网络...\n");
}
//初始化模板
static void ADM_init(void *obj)
{
AMDCpuStart_t *amd = (AMDCpuStart_t*)obj;
printf("AMD CPU 上电初始化流程: \n");
amd->init_peripheral(amd);
amd->init_disk(amd);
amd->init_memory(amd);
amd->init_net(amd);
}
//AMD构造函数 创建一个结构体指针
AMDCpuStart_t* construct_amd_cpu(void)
{
AMDCpuStart_t* obj = (AMDCpuStart_t*)malloc(sizeof(AMDCpuStart_t));
obj->init = ADM_init;
obj->init_disk = ADM_init_disk;
obj->init_memory = ADM_init_memory;
obj->init_net = ADM_init_net;
obj->init_peripheral = ADM_init_peripheral;
return obj;
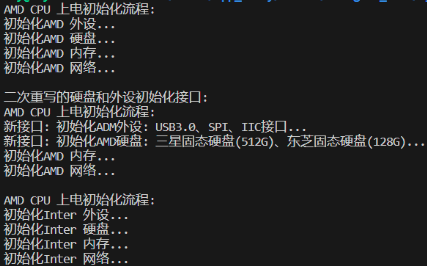
}测试程序:如下,先创建一个 AMD 的对象,调用 init()模块进行初始化,然后对 init_peripheral()、**init_disk()**指向新的函数,修改接口,这样保证了我们模块流程不变,但是可以改变一些具体的细节。最后创建 Intel 对象,调用 init()函数模板进行初始化。
//二次重写 AMD 外设初始化程序
void ADM_init_peripheral_v1(void *obj)
{
printf("新接口: 初始化 ADM 的外设: USB3.0、SPI、IIC接口...\n");
}
//二次重写 AMD 硬盘初始化程序
void ADM_init_disk_V1(void *obj)
{
printf("新接口: 初始化AMD 硬盘: 三星固态硬盘(512G)、东芝固态硬盘(128G)...\n");
}
int main(void)
{
Interface_t *cpu=NULL;
//创建一个AMD对象
cpu = (Interface_t*)construct_amd_cpu();
//调用模板 初始化AMD CPU
cpu->init(cpu);
printf("\n二次重写的硬盘和外设初始化接口:\n");
//给函数指针二次赋值(等于重写),便于修改添加新概念
cpu->init_peripheral = ADM_init_peripheral_v1;
//给函数指针二次赋值(等于重写),便于修改添加新概念
cpu->init_disk = ADM_init_disk_V1;
//调用模块,修改了初始化硬盘、初始化外设接口
cpu->init(cpu);
free(cpu);
cpu = NULL;
printf("\n");
//创建一个Intel CPU对象
cpu = (Interface_t*)construct_intel_cpu();
//调用Intel CPU初始化模板
cpu->init(cpu);
free(cpu);
cpu = NULL;
return 0;
}测试结果: 与预期一致,第二次调用amd的init()模板时,使用的就是新接口的功能。
在传统的控制逻辑程序中,我们常常使用 if、else if、else 或者 switch case 来进行判断处理,但是当业务需求逻辑复杂了,使用这种方式实现往往会变得很复杂,且写出的代码不易维护。此时采用有限状态机,这个问题将会变得容易起来。
有限状态机,把复杂的控制逻辑进行分解成有限个稳定状态,组成闭环系统,通过事件触发,让状态机按设定的顺序处理事务。状态机的原理如下:在当前状态下,发生某个事件后转移到下一个状态,然后决定执行的功能动作。
有限状态机有四个点: 事件、当前状态、相应的动作、下一个状态,把这四个特性封装进结构体,建成一个表(结构体数组),循环遍历数组,根据事件触发,取出满足条件的状态项并执行对应动作函数。
本文以我们平常使用接、打电话为例,画出状态图,使用状态机实现对应的逻辑程序。下图是根据接、打电话需求逻辑画出的状态图,最开始事件和状态处于空闲,当有事件触发,会使状态转移并触发执行相应的动作函数。
下图,圆圈中代表状态,箭头所指方向代表状态转移的方向,线条上的字则代表触发的事件。例如:初始是空闲状态,发生响铃事件,状态转移为响铃态,并执行响铃态的动作。
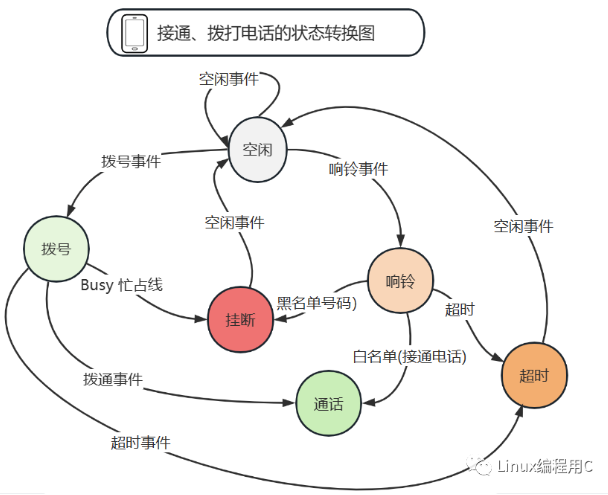
*有限状态机程序设计,主要四大点:* 事件,当前态,动作(执行函数),次态。
*事件:* 即状态图中线条上的字,使用枚举类型进行定义,可以按照实际需求进行增加、修改。
typedef enum
{
E_IDLE, /* 空闲 */
E_BELL, /* 铃声 */
E_WHITE_LIST, /* 白名单 */
E_BLACK_LIST, /* 黑名单 */
E_FINISH, /* 通话结束 */
E_BUSY, /* 占线忙 */
E_CONNECT, /* 接通 */
E_DIAL, /* 拨号 */
E_TIME_OUT /* 超时 */
}Event; /* 触发事件,由外部到来 */****状态:****状态,表示当前业务中所以的状态,即状态图圆圈中的字,使用枚举类型进行定义。
typedef enum
{
S_IDLE=0, /* 空闲 */
S_BELL, /* 响铃 */
S_TALK, /* 通话 */
S_HANGUP, /* 挂断 */
S_DIAL, /* 拨号 */
S_TIMEOUT /* 超时 */
}State; /* 当前状态 */****动作(执行的函数):****使用函数指针进行定义,便于实现 C 语言的"多态",执行不同函数。
void (*event_action)(Event *event, void *);**状态表:**有了以上的了解,便可以开始今天的重点了--状态表,使用结构体定义。
typedef struct FsmTable
{
Event event; /* 触发事件 */
State cur_sta; /* 当前状态 */
void (*event_action)(Event *event, void *); /* 动作函数 */
State next_sta; /* 跳转状态 */
}FsmTable;根据这个定义,我们使用结构体数组来做一个驱动表,使用方式如下:这里包含接、打电话全部的处理流程,后续根据事件进行触发执行动作,替代大量 if、else 的逻辑判断,使其逻辑清晰。
FsmTable fsmtb[] = {
/* 事件 当前状态 动作 下一个状态 */
{ E_IDLE, S_IDLE, idle_func, S_IDLE },
{ E_BELL, S_IDLE, bell_func, S_BELL },
{ E_DIAL, S_IDLE, dial_func, S_DIAL },
{ E_TIME_OUT, S_DIAL, timeout_func, S_TIMEOUT },
{ E_TIME_OUT, S_BELL, timeout_func, S_TIMEOUT },
{ E_BUSY, S_DIAL, hangup_func, S_HANGUP },
{ E_CONNECT, S_DIAL, talk_func, S_TALK },
{ E_WHITE_LIST, S_BELL, talk_func, S_TALK },
{ E_BLACK_LIST, S_BELL, hangup_func, S_HANGUP },
{ E_FINISH, S_TALK, hangup_func, S_HANGUP },
{ E_IDLE, S_HANGUP, idle_func, S_IDLE },
{ E_IDLE, S_TIMEOUT, idle_func, S_IDLE }
};
//限于篇幅,此处展示部分的动作函数
void talk_func(Event *event, void *args)
{
int ret=0;
printf("通话中... ");
printf("【输入1-9, 通话结束】:");
scanf("%d", &ret);
*event = E_FINISH; //触发下一个事件
//此处做演示,直接更新触发事件,
//实际中可根据传入的参数,进行更新触发事件,
//或根据外部条件进行触发
}
void hangup_func(Event *event, void *args)
{
printf("\n挂断电话...\n\n");
*event = E_IDLE; //更新触发下一个事件
}有限状态机的数据结构:包含了以上定义的数据结构
typedef struct FSM
{
FsmTable *fsmtb; /* 状态迁移表 */
State cur_sta; /* 状态机当前状态 */
Event event; /* 当前的事件 */
uint8_t sta_max_n; /* 状态机状态迁移数量 */
}FSM;有限状态机的实现函数就两个,一个是创建创建有限状态机结构体指针并初始化的函数,一个是需要被循环执行的事件处理函数。
/**
* @breif: 遍历状态表,处理事件
* @fsm: 创建好的FSM结构体指针
* @args: 传入的参数
* @return: 1:成功
*/
int run_fsm_action(FSM* fsm, void *args)
{
int max_n = fsm->sta_max_n, i=0;
State cur_sta = fsm->cur_sta;
FsmTable *fsmtb = fsm->fsmtb;
if(!fsm) return -1;
for(i=0; i<max_n; ++i){
if(fsmtb[i].cur_sta == cur_sta && fsmtb[i].event == fsm->event){
fsmtb[i].event_action(&fsm->event, args); /* 调用对应的处理函数 */
fsm->cur_sta = fsmtb[i].next_sta; /* 转移到下一个状态 */
break;
}
}
return 0;
}
/**
* @brief: 创建一个FSM结构体指针
* @fsmtb: 填充好的状态表
* @state: 初始状态
* @event: 初始事件
* @num: 状态表项个数
* @return: 返回一个FSM结构体指针
*/
FSM* create_fsm(FsmTable* fsmtb, State state, Event event, int num)
{
FSM* fsm = (FSM*)malloc(sizeof(FSM));
fsm->cur_sta = state;
fsm->event = event;
fsm->fsmtb = fsmtb;
fsm->sta_max_n = num;
return fsm;
}1.定义有限状态机结构体表
FsmTable fsmtb[] = {
/* 事件 当前状态 动作 下一个状态 */
{ E_IDLE, S_IDLE, idle_func, S_IDLE },
{ E_BELL, S_IDLE, bell_func, S_BELL },
{ E_DIAL, S_IDLE, dial_func, S_DIAL },
......2.定义对应的动作函数
//空闲处理函数
void idle_func(Event *event, void *args)
{
//...
}
//响铃处理函数
void bell_func(Event *event, void *args)
{
//...
}
//拨号处理函数
void dial_func(Event *event, void *args)
{
//...
}3.创建结构体并循环运行事件处理函数
int main(void)
{
int num = sizeof(fsmtb)/sizeof(fsmtb[0]);
FSM *fsm = create_fsm(fsmtb, S_IDLE, E_IDLE, num);
while(1)
{
run_fsm_action(fsm, NULL); //循环运行
}
return 0;
}**编译:**在Linux环境中,输入make进行编译,mainApp是生成的可执行文件。
测试程序:
int main(void)
{
int num = sizeof(fsmtb)/sizeof(fsmtb[0]);
FSM *fsm = create_fsm(fsmtb, S_IDLE, E_IDLE, num);
while(1)
{
run_fsm_action(fsm, NULL); //循环运行
}
return 0;
}1.打电话流程测试图如下,通过输入进行触发事件,最开始是空闲,输入2拨号,触发拨号事件,进入拨号态,输入2接通接通电话,进入通话态,输入0接收通话,挂断电话,回到空闲态。可结合状态转换图一起看,更清晰。

2.接电话流程测试图如下,输入1触发响铃事件,进入响铃态,输入2接通电话,进入通话态,输入0结束通话,挂断电话,回到空闲态。

3.其他流程也和状态转换图流程符合。
有限状态机要点总结:
1.有多少个状态就有多少个处理函数。
2.状态图中有多少个事件连接线,表中就有多少项处理。
3.事件的作用是把状态从当前态转换到下一个状态。
4.发生事件后,执行的是下一个状态动作函数,即箭头所指的状态。例如:发生响铃事件,执行响铃态的动作函数。
通过上述的了解,我们发现通过有限状态机可以实现业务中比较复杂的逻辑程序,且易于扩展,便于维护。
1.策略模式简介
策略模式 (Strategy)也叫是行为模式之一,它对一系列的算法加以封装,为所有算法定义一个抽象的算法接口,并通过继承该抽象算法接口对所有的算法加以封装和实现,具体的算法选择交由客户端决定(策略)。Strategy 模式主要用来平滑地处理算法的切换。
2.策略模式特点
准备一组算法,并将每一个算法封装起来,使得它们可以互换。
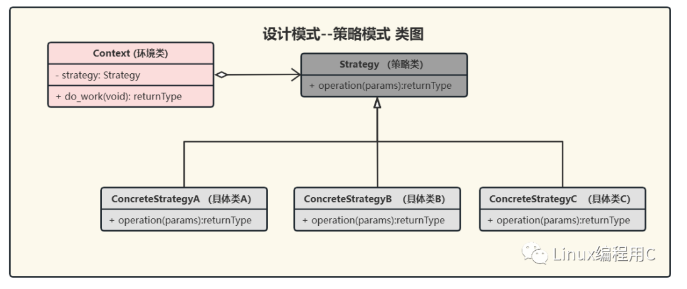
3.UML 类图
类图描述: 定义一个抽象接口类 Strategy,具体类 A、B、C 通过继承实现接口中的定义。Context 环境类,内部包含 Strategy 定义的对象,调用 Strategy 类的 operation(),通过多态的发生实现不同的操作。
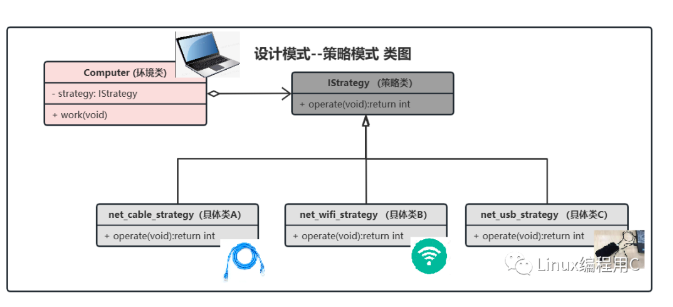
本片以笔记本电脑实现联网功能为例,有 3 种联网方式,通过网线联网、WiFi 联网、USB 连接手机提供网络。为了举例,假设每一种联网方式对于笔记本电脑来说都是一种操作算法,我们把这三种算法抽象一个公共类 Strategy,如果 Computer(电脑)联网访问 Strategy 提高的统一抽象接口,通过发生“多态”实现不同的联网功能。
具体的策略设计模式的类图如下:
1.策略模式抽象接口结构体的定义
typedef struct Istrategy
{
int (*operate)(void* obj);
void (*free)(void* obj);
}Istrategy;2.具体策略类实现, 使用网线连接网络结构体的实现
typedef struct net_cable_strategy
{
int (*operate)(void* obj); //“继承”抽象接口函数
void (*free)(void* obj); //“继承”抽象接口函数
float rate; //自身特有属性
float len; //自身特有属性
}net_cable_strategy;
//使用网线联网函数实现
static int net_cable_operate(void *obj)
{
if(!obj) return -1;
net_cable_strategy* nobj = (net_cable_strategy*)obj;
printf("使用【网线】给电脑连接网络...\n");
printf("网络速率: %.2fM/s\n", nobj->rate);
printf("网线长度: %.0fm\n", nobj->len);
}
//释放结构体内存
static void net_cable_free(void *obj)
{
if(!obj) return;
free(obj);
obj = NULL;
}
//“构造函数” 创建一个对象
net_cable_strategy* construct_net_cable(void)
{
net_cable_strategy* obj = (net_cable_strategy*)malloc(sizeof(net_cable_strategy));
if(!obj) return NULL;
obj->operate = net_cable_operate;
obj->free = net_cable_free;
obj->rate = 53.34;
obj->len = 100;
return obj;
}3.具体实现类,通过连接 WIFI 提供网络
typedef struct net_wifi_strategy
{
int (*operate)(void* obj); //“继承”抽象接口函数
void (*free)(void* obj); //“继承”抽象接口函数
float rate; //自身特有属性
char *describe;//自身特有属性
}net_wifi_strategy;
//使用WIFI联网函数实现
static int net_wifi_operate(void *obj)
{
if(!obj) return -1;
net_wifi_strategy* nobj = (net_wifi_strategy*)obj;
printf("使用【WIFI】给电脑连接网络...\n");
printf("网络速率: %.2fM/s\n", nobj->rate);
printf("描述:%s\n", nobj->describe);
}
//释放内存
static void net_wifi_free(void *obj)
{
if(!obj) return;
net_wifi_strategy* nobj = (net_wifi_strategy*)obj;
if(nobj->describe) free(nobj->describe);
nobj->describe = NULL;
free(obj);
obj = NULL;
}
//“构造函数” 创建一个对象
net_wifi_strategy* construct_net_wifi(void)
{
net_wifi_strategy* obj = (net_wifi_strategy*)malloc(sizeof(net_wifi_strategy));
if(!obj) return NULL;
obj->operate = net_wifi_operate;
obj->free = net_wifi_free;
obj->rate = 23.34;
obj->describe = (char*)malloc(64);
sprintf(obj->describe, "WIFI4, 802.11n, 频段 2.4GHz, 理论最大速率 600Mbps");
return obj;
}4.使用 USB 连接手机通过网络定义与实现和上面的类似,限于篇幅,不再赘述。
下面是 main 函数,测试策略模式功能。通过“构造函数”创建对象的联网对象,实现不同的联网功能,而调用接口和流程保持不变。
int main(void)
{
printf("Test Strategy Mode...\n");
Istrategy *net = NULL;
computer* com_obj = NULL;
net = (Istrategy *)construct_net_cable();
com_obj = construct_computer(net);
com_obj->work(com_obj);
com_obj->free(com_obj);
printf("-----------split-----------\n\n");
net = (Istrategy *)construct_net_wifi();
com_obj = construct_computer(net);
com_obj->work(com_obj);
com_obj->free(com_obj);
printf("-----------split-----------\n\n");
net = (Istrategy *)construct_net_usb();
com_obj = construct_computer(net);
com_obj->work(com_obj);
com_obj->free(com_obj);
printf("-----------split-----------\n\n");
return 0;
}测试结果:
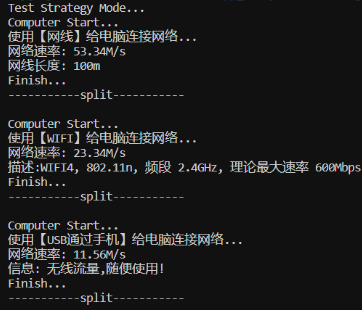
策略模式的优点:
A. 多重条件语句不易维护,而使用策略模式可以避免使用多重条件语句。
B. 策略模式提供了一系列的可供重用的算法族,恰当使用继承可以把算法族的公共代码转移到父类里面,从而避免重复的代码。
C. 策略模式可以提供相同行为的不同实现,客户可以根据不同时间或空间要求选择不同的。
D. 策略模式提供了对开闭原则的完美支持,可以在不修改原代码的情况下,灵活增加新算法。
E. 策略模式把算法的使用放到环境类中,而算法的实现移到具体策略类中,实现了二者的分离。
缺点:
A. 客户端必须理解所有策略算法的区别,以便适时选择恰当的算法类。 B. 策略模式造成很多的策略类。
虽然C语言是面向过程的编程语言,但是我们在设计程序的时候,可以考虑用面向对象的方式去设计,这样提高我们程序的“高内聚、低耦合”特性,便于维护。
Composite 模式也叫组合模式,是构造型的设计模式之一。通过递归手段来构造树形的对象结构,并可以通过一个对象来访问整个对象树。组合模式也叫部分-整体模式、合成模式或对象树如果要实现的功能的结构可以被抽象成树状结构,就非常适合使用组合模式。
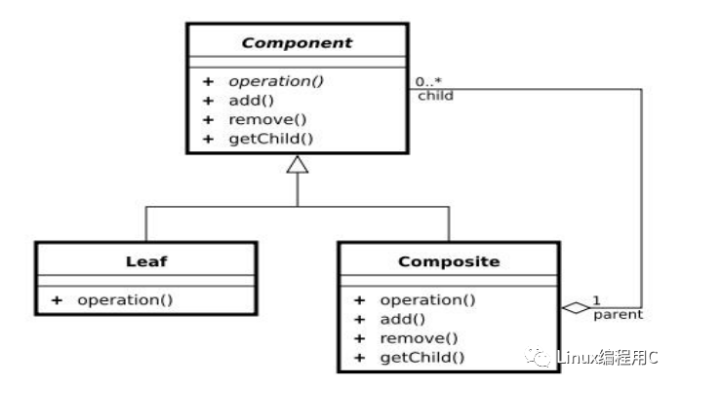
下图是组合设计模式的类图:
Component (树形结构的节点抽象): 1.为所有的对象定义统一的接口(公共属性,行为等的定义); 2. 提供管理子节点对象的接口方法; 3. [可选]提供管理父节点对象的接口方法。
Leaf (树形结构的叶节点),Component 的实现子类,Composite(树形结构的枝节点)。
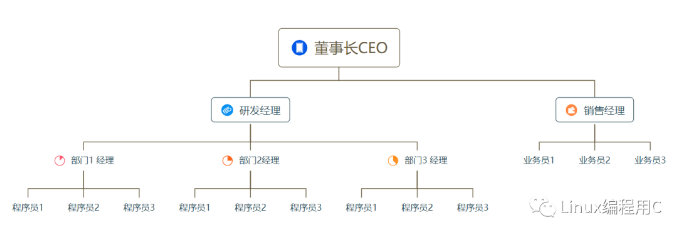
像下图这种人力资源架构的就很适合采用组合设计模式来设计。
接下来我们使用代码实现该功能。
定义对象结构体,此处采用的是结构体指针数组存储子节点的指针,优点是简单明了,缺点是不能动态扩容,实际使用中,可以采用链表替代指针数组,实现动态扩展子节点。
不管采用指针数组、还是链表存储,都不影响实现组合模式的设计思想。
#define MAX_SUB_NODE (16U) //一个节点下面的最大子节点个数
typedef struct IComposite_t
{
//对象处理函数
int (*work)(struct IComposite_t *obj);
//添加子节点
int (*add)(struct IComposite_t *obj, struct IComposite_t* node);
char info[128]; //节点信息描述
int subnode_cnt; //子节点个数
struct IComposite_t *subnode[MAX_SUB_NODE]; //指向子节点的结构体指针数组
}IComposite_t;2.实现函数指针指向的具体函数实体。
a. int (*work)(struct IComposite_t *obj); 函数的具体实现,该函数实现特别简单,打印一下对应节点对象的信息,实际使用可以在此函数中实现对应节点对象具体操作,处理工作等。
static int work_something(IComposite_t *obj)
{
if(!obj || !obj->info) return -1;
printf("%s\n", obj->info);
//do something
return 0;
}b.int (*add)(struct IComposite_t obj, struct IComposite_t node);具体实现,该函数实现的功能是往子节点添加节点,前面一个参数父节点指针,后面一个参数新添加的节点指针。
static int add_node(IComposite_t *obj, IComposite_t* node)
{
if(!obj || !node || obj->subnode_cnt >= MAX_SUB_NODE || obj->subnode_cnt<0) return -1; //添加失败
obj->subnode[obj->subnode_cnt] = node;
++(obj->subnode_cnt); //子节点加一
return 0;
}c.构造函数的实现,即创建一个结构体对象。申请内存,给函数指针赋值,传参给info赋值,最后返回该节点。
IComposite_t* construction_composite(char *name, char *info)
{
IComposite_t* node = (IComposite_t*)malloc(sizeof(IComposite_t));
if(!node) return NULL;
node->add = add_node; //函数指针赋值
node->work = work_something; //函数指针赋值
snprintf(node->info, 128, "%s : %s", name, info);
node->subnode_cnt = 0; //初始化子节点为0
return node;
}3.接下来是遍历对象树函数的实现:
通过递归调用,此函数便可以访问对象树上所有的节点,调用对应节点上面的work函数指针,使得每个节点都可以工作。
void order_tree(IComposite_t* root, int level)
{
if(!root) return;
int i=0;
for(i=0; i<level; i++){
printf("\t");
}
root->work(root); //工作
for( i=0; i<root->subnode_cnt; ++i){
order_tree(root->subnode[i], level+1);
}
}最后一个函数是释放对象树内存:也是递归调用实现的。
void destroy_tree(IComposite_t* root)
{
if(!root) return;
int i=0;
for(i=0; i<root->subnode_cnt; ++i){
destroy_tree(root->subnode[i]);
}
free(root);
root = NULL;
}使用流程,main函数具体实现:实现的功能是上面那个人力架构图。
int main(void)
{
IComposite_t* ceo = construction_composite("CEO", "批阅文件");
IComposite_t* manager1 = construction_composite("研发总经理", "技术架构规划设计");
ceo->add(ceo, manager1);
IComposite_t* department_manager1 = construction_composite("一部门经理", "项目规划");
manager1->add(manager1, department_manager1);
IComposite_t* coder1 = construction_composite("程序员1", "敲代码");
department_manager1->add(department_manager1, coder1);
IComposite_t* coder2 = construction_composite("程序员2", "敲代码");
department_manager1->add(department_manager1, coder2);
IComposite_t* coder3 = construction_composite("程序员3", "敲代码");
department_manager1->add(department_manager1, coder3);
IComposite_t* department_manager2 = construction_composite("二部门经理", "项目规划");
manager1->add(manager1, department_manager2);
coder1 = construction_composite("程序员1", "敲代码");
department_manager2->add(department_manager2, coder1);
coder2 = construction_composite("程序员2", "敲代码");
department_manager2->add(department_manager2, coder2);
coder3 = construction_composite("程序员3", "敲代码");
department_manager2->add(department_manager2, coder3);
IComposite_t* department_manager3 = construction_composite("三部门经理", "项目规划");
manager1->add(manager1, department_manager3);
coder1 = construction_composite("程序员1", "敲代码");
department_manager3->add(department_manager3, coder1);
coder2 = construction_composite("程序员2", "敲代码");
department_manager3->add(department_manager3, coder2);
coder3 = construction_composite("程序员3", "敲代码");
department_manager3->add(department_manager3, coder3);
IComposite_t* manager2 = construction_composite("销售总经理", "开拓市场");
ceo->add(ceo, manager2);
IComposite_t *saler1 = construction_composite("销售员1", "跑业务");
manager2->add(manager2, saler1);
IComposite_t *saler2 = construction_composite("销售员2", "跑业务");
manager2->add(manager2, saler2);
IComposite_t *saler3 = construction_composite("销售员3", "跑业务");
manager2->add(manager2, saler3);
order_tree(ceo, 0);
destroy_tree(ceo);
return 0;
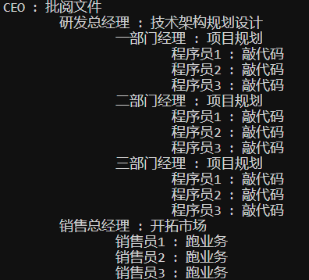
}运行输出信息:
组合模式的使用场景:1.维护和展示部分-整体关系,比如菜单、文件、文件夹管理等。2.从整体中能够独立出部分模块或功能的场景。只要体现部分-整体的关系时,考虑一下组合模式吧。
虽然C语言是面向过程的编程语言,但是我们在设计程序的时候,可以考虑用面向对象的方式去设计,这样提高我们程序的“高内聚、低耦合”特性,便于维护。
一、简介
观察者模式是行为模式之一,它的作用是当一个对象的状态发生变化时,能够自动通知其他关联对象,自动刷新对象状态。该模式提供给关联对象一种同步通信的手段,使某个对象与依赖它的其他对象之间保持状态同步。
典型应用:
今天我们打算实现的是可以监听各个对象状态信息,也可以向各个对象广播信息,即发布和订阅功能。
以一个简单监测环境系统为例,有一个 Master(主)负责监测各对象状态,还可以向各模块发布信息。有多个 Slave(从)模块,比如环境温度采集模块(temperature_slave)、环境湿度采集模块(humidity_slave)等,各个采集模块向主机 Matser 上报当前采集状态,主机可以向各个 slave 发布控制指令是否采集,这样验证发布与订阅功能。
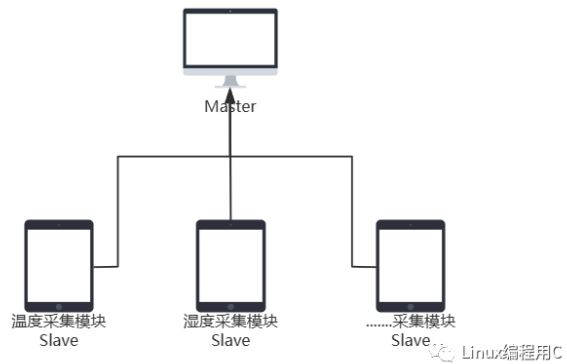
实现思路:各个 slave 模块封装成结构体(对象),定义一个抽象的对象(ISlave),然后定义一个双向链表,链表节点包含的是抽象 slave 对象,master(主)负责管理这个链表,向链表上的对象发布信息,或者收集信息,以此实现发布和订阅。
本例中使用的Linux内核中的双向链表,示意如下:

所谓的抽象对象(ISlave)即把所有 slave 对象公共部分提取出来定义一个结构体。例如:本例中ISlave_t抽象对象定义如下,定义这些函数指针以及变量都是temperature_slave_t以及humidity_slave_t公有的,把这些公有部分提取出来作为一个抽象结构体,后面程序中直接使用抽象结构体ISlave_t实现逻辑功能,然后通过ISlave_t指针指向不同temperature_slave_t、humidity_slave_t具体结构体,则可以使用对应功能,发生“多态”。比如:
//多态实现例子
int main(void)
{
//定义抽象对象指针
ISlave_t *slave;
//创建具体对象指针
temperature_slave_t *tslave = create_temperature_slave();
//创建具体对象指针
humidity_slave_t *hslave = create_humidity_slave();
//发生多态1
slave = tslave;
//此时调用的就是temperature_slave_t的send函数
//因为slave指向temperature_slave_t的指针
slave->send(slave);
//发生多态2
slave = hslave;
//此时调用的就是humidity_slave_t的send函数
//因为slave指向humidity_slave_t的指针
slave->send(slave);
//这样做的好处是,程序中可以先使用抽象结构体的定义去实现逻辑功能。
//功能根据抽象结构体指向不同具体结构体指针,动态实现不同的功能。
//便于维护。
return 0;
}Slave 的各个模块的定义如下:
//定义的slave基类
typedef struct ISalve_t
{
void (*recv)(struct ISalve_t *obj, info_t *info); //收到来自Master的信息
void* (*send)(struct ISalve_t *obj); //向Master发生信息
void (*free)(struct ISalve_t *obj); //释放内存
struct list_head node; //链表节点
info_t info;
}ISalve_t;
//温度模块
typedef struct temperature_slave_t
{
void (*recv)(struct ISalve_t *obj, info_t *info); //收到来自Master的信息
void* (*send)(struct ISalve_t *obj); //向Master发生信息
void (*free)(struct ISalve_t *obj); //释放内存
struct list_head node; //链表节点
info_t info;
//-----------splite---------------------
//下面可以根据自己情况添加各种成员变量
void (*get_temperature)(struct ISalve_t *obj);
float temperature;
}temperature_slave_t;
typedef struct humidity_slave_t
{
void (*recv)(struct ISalve_t *obj, info_t *info); //收到来自Master的信息
void* (*send)(struct ISalve_t *obj); //向Master发生信息
void (*free)(struct ISalve_t *obj); //释放内存
struct list_head node; //链表节点
info_t info;
//-----------splite---------------------
//下面可以根据自己情况添加各种成员变量
void (*get_humidity)(struct ISalve_t *obj);
float humidity; //湿度
}humidity_slave_t;温度模块 temperature_slave_t 模块的具体定义:限于篇幅,未展示湿度采集模块代码,但是与温度采集模块代码几乎一致。
/**
* @brief:处理收到来自master信息的函数
* @obj: slave指针,传入便于访问内部变量
* @info: 具体信息
* @return: none
*/
static void slave_temperature_recv(struct ISalve_t *obj, info_t *info) //收到来自Master的信息
{
if(!obj || !info) return;
obj->info.collection_state = info->collection_state;
printf("温度采集模块 收到来自Mater指令: [%s] 采集数据\n", obj->info.collection_state==1?"开始":"停止");
}
/**
* @brief:向master发送信息
* @obj:slave指针,传入便于访问内部变量
* @return: info信息
*/
static void* slave_temperature_send(struct ISalve_t *obj) //向Master发生信息
{
temperature_slave_t* tslave = (temperature_slave_t*)obj;
if(!obj) return NULL;
tslave->get_temperature(obj);
return &obj->info; //把信息返回出去
}
/**
* @brief:获取温度数据(rand随机生成的)
* @obj:slave指针,传入便于访问内部变量
* @return:none
*/
static void slave_get_temperature(struct ISalve_t *obj)
{
temperature_slave_t* tslave = (temperature_slave_t*)obj;
if(!obj) return;
tslave->temperature = rand()%50; //取随机数
tslave->info.is_normal = tslave->temperature > 32 ? 0 : 1;
}
/**
* @brief:释放内存资源
* @return:none
*/
static void slave_free(struct ISalve_t *obj) //释放内存
{
if(!obj) return;
free(obj);
}
/**
* @brief:temperature_slave的构造函数,创建一个结构体指针
* @return: slave指针
*/
temperature_slave_t* construct_temperature_slave(void)
{
temperature_slave_t* slave = (temperature_slave_t*)malloc(sizeof(temperature_slave_t));
//函数指针指向具体的函数,后续直接使用函数指针即可调用对应函数
slave->free = slave_free;
slave->send = slave_temperature_send;
slave->recv = slave_temperature_recv;
slave->get_temperature = slave_get_temperature;
slave->info.id = TEMPERATURE;
return slave;
}Master 模块的定义:
typedef struct IMaster_t
{
struct list_head hlist; //缓存对象的链表
int (*publish)(struct IMaster_t *obj, info_t *info); //向所有的salve广播信息
int (*subscriber)(struct IMaster_t *obj);
int (*add)(struct IMaster_t *obj, ISalve_t *salve_obj); //订阅salve的信息
int (*remove)(struct IMaster_t *obj, ISalve_t *salve_obj); //订阅salve的信息
void (*free)(void *obj); //释放内存
}IMaster_t;
/**
* @brief:向各个slave模块发布信息
* @obj: master指针,传入进去便于访问内部变量
* @info: 向各模块发布的信息
* @return: -1:err 0:ok
*/
static int master_publish(IMaster_t *obj, info_t *info)
{
struct list_head *pos=NULL;
ISalve_t *salve=NULL;
if(!obj) return -1;
//遍历双向链表,向各个slave对象发布信息
list_for_each(pos, &(obj->hlist)){
salve = list_entry(pos, ISalve_t, node);
salve->recv(salve, info); //向slave广播信息,对应salve来说是收信息
}
return 0;
}
/**
* @brief:定义各个slave的对象的信息
* @obj: master指针,传入进去便于访问内部变量
* @return: -1:err 0:ok
*/
static int matser_subscriber(struct IMaster_t *obj)
{
if(!obj) return -1;
struct list_head *pos=NULL;
ISalve_t *salve=NULL;
void *info = NULL;
//遍历双向链表,获取各个slave的信息
list_for_each(pos, &(obj->hlist)){
salve = list_entry(pos, ISalve_t, node);
info = salve->send(salve); //收到来自slave的info信息
//处理slave的信息
//...........
switch (((info_t*)info)->id)
{
case TEMPERATURE:
printf("温度采集模块: ");
break;
case HUMIDITY:
printf("湿度采集模块: ");
break;
default:
break;
}
if(((info_t*)info)->is_normal==1){
printf("采集数据值:正常!\n");
}else{
printf("采集数据值:异常!\n");
}
}
return 0;
}
/**
* @brief:向master的链表添加salve对象
* @obj: master指针,传入进去便于访问内部变量
* @salve_obj:要添加的salve对象指针
* @return: -1:err 0:ok
*/
static int master_add_slave(IMaster_t *obj, ISalve_t *salve_obj)
{
if(!obj || !salve_obj) return -1; //传入参数不正确
list_add_tail(&(salve_obj->node), &(obj->hlist)); //将salve对象加入链表
return 0;
}
/**
* @brief:从master的链表移除slave节点
* @obj: master指针,传入进去便于访问内部变量
* @salve_obj:要移除的salve对象指针
* @return: -1:err 0:ok
*/
static int master_remove_salve(struct IMaster_t *obj, ISalve_t *salve_obj) //订阅salve的信息
{
struct list_head *pos=NULL, *n=NULL;
if(!obj || !salve_obj) return -1;
list_del(&(salve_obj->node));
return 0;
}
/**
* @brief: 释放master对象内存
* @obj: master指针,传入进去便于访问内部变量
*/
static void master_free(void *obj)
{
if(!obj) return;
free(obj);
}
/**
* @brief:master的构造函数,创建一个master对象指针
* @return:返回一个master指针
*/
IMaster_t *construct_master(void)
{
IMaster_t* obj = (IMaster_t*)malloc(sizeof(IMaster_t));
INIT_LIST_HEAD(&obj->hlist);
//通过函数指针指向具体函数,后续直接调用函数指针即可,下同
obj->add = master_add_slave;
obj->remove = master_remove_salve;
obj->publish = master_publish;
obj->subscriber = matser_subscriber;
obj->free = master_free;
return obj;
}测试的 main 函数内容如下:创建一个 master 和温度 slave、湿度 slave,向各个 slave 发布信息,以及获取各个 slave 的信息,测试 remove slave 对象等功能。
int main(void)
{
int i=0;
srand(time(NULL));
info_t info;
//创建一个master对象
IMaster_t *master = construct_master();
//创建一个湿度slave对象
humidity_slave_t *hslave = construct_humidity_slave();
//创建一个温度slave对象
temperature_slave_t *tslave = construct_temperature_slave();
//将两个slave对象添加到master监测链表
master->add(master, (ISalve_t*)hslave);
master->add(master, (ISalve_t*)tslave);
//给slave模块发射控制指令,停止指令
info.collection_state = 0;
master->publish(master, &info);
//给slave模块发射控制指令,开始指令
info.collection_state = 1;
master->publish(master, &info);
//监测各个模块信息,内部采集数据rand随机生成的
for(i=0; i<5; ++i){
printf("--------------------------\n");
printf("监测各个模块: \n");
master->subscriber(master);
}
//remove一个温度slave对象
master->remove(master, (ISalve_t*)tslave);
//现在只有一个湿度slave对象
printf("--------remove 温度模块后------------------\n");
printf("监测各个模块: \n");
master->subscriber(master);
//释放各个对象内存
master->free(master);
hslave->free((ISalve_t*)hslave);
tslave->free((ISalve_t*)tslave);
return 0;
}运行结果:

虽然C语言是面向过程的编程语言,但是我们在设计程序的时候,可以考虑用面向对象的方式去设计,这样提高我们程序的“高内聚、低耦合”特性,便于维护。
访问者模式(Visitor Pattern),用于封装一些作用于某种数据结构中的各元素操作,可以在不改变数据结构的前提下定义作用这些新元素的操作。简单来讲就是可以访问对象、模块(数据结构)中已定义好的数据,通过访问得到这些数据,进行一些新的操作,而不用修改原有的代码。这样做有什么好处呢?答案是分离对象的数据和行为,可以再不修改已有类对象情况下,增加一些新的操作。
举个例子:逛购物网站时,网站上面有琳琅满目的商品,商品的属性有名字、单价、重量、数量、尺寸、颜色等等,这些属性就定义到一起称为它的数据结构,我们浏览这些商品的时候,便会关注商品的单价、数量等,此时我们便是访问者,访问商品的属性,根据单价和数量算出支付金额。我们买了商品,需要快递公司邮寄,快递公司此时也是一个访问者,访问商品的属性,不过他关注的数据和我们不一样,他只关注你商品的重量,尺寸,距离等,算出邮费。这个例子说明不同的访问者访问同样的数据,做出不同操作,而不修改原有定义的结构,这个就是访问者模式用途。本例中实现访问者设计模式的示意图如下:
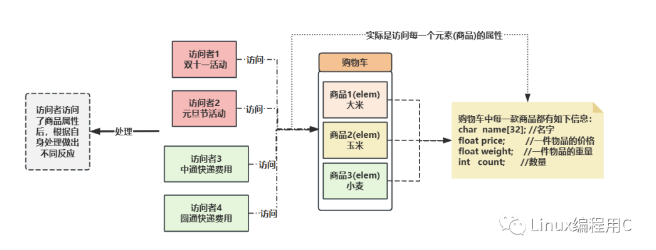
访问者模式的UML图如下:
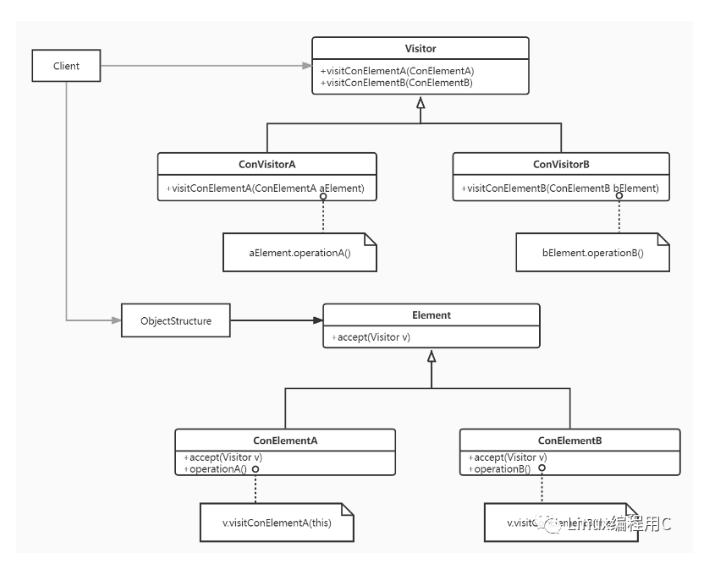
Visitor是定义的抽象接口类,ConVisitorA、ConVisitorB是继承抽象接口实现具体的访问者。Element是定义抽象元素(被访问者),ConElement、ConElementB是继承抽象接口实现具体元素类。ObjectStructure是定义的管理元素类的,供用户client使用。
根据上述的例子与 UML 图,我们首先需要定义一个抽象的访问者"类"(结构体,下同),两个接口,一个是访问元素的函数指针 visite,一个是释放内存的函数指针 free。还要定义一个抽象元素"类",接受访问者访问的函数指针 accept 与释放内存的函数指针 free。
//元素属性,实际可根据情况自定义
typedef struct Info_t
{
char name[32]; //名字
float price; //一件物品的价格
float weight; //一件物品的重量
int count; //数量
}Info_t;
//抽象访问者接口定义
typedef struct IVisitor_t
{
//访问元素
void (*visite)(struct IVisitor_t* obj, struct IElement_t* elem);
//释放内存
void (*free)(struct IVisitor_t *obj);
}IVisitor_t;
//抽象元素(被访问者定义)
typedef struct IElement_t
{
//定义的属性
Info_t info;
//接受访问
void (*accept)(struct IElement_t* obj, struct IVisitor_t* visitor);
//释放内存
void (*free)(struct IElement_t* obj);
//链表节点,便于加入链表(linux内核链表)
struct list_head node;
}IElement_t;定义好抽象接口后,我们需要实现具体定义,即面向对象语言中的继承,我们使用 C 语言,没有继承怎么办,我们只需要定义包含且顺序与抽象定义一样的元素,其他的定义可随便添加。为什么这样做?这样为了我们定义某些函数接口时候使用抽象接口定义结构体,实际调用过程中传入具体定义结构体指针,只要保证结构体前面定义一样,即使结构体名称不同,在进行指针强制转换时候,保证访问抽象元素顺序一致,便可正确访问数据。举个例子:
//抽象接口
struct A
{
void (*func)(void);
void (*free)(void);
};
//定义实现即继承A
struct B
{
void (*func)(void);
void (*free)(void);
//保证前面顺序一致
//-----------------
int a;
char b;
float c;
//........等其他随便定义
};
//使用抽象接口定义函数
//实际中通过传入不同的结构体指针
//实现内部不同的功能
int process(A *a)
{
a->func();
a->free();
}
int main(void)
{
B *b = create_b();
//可以传入"继承"A的结构体指针
//传入不同的指针实现不同的功能
//且不用修改process函数内部流程
//实现“高内聚、低耦合”,符合设计模式中的“开闭原则”
process(b);
}接下来我们回归主题,实现对应的访问者和元素:首先实现访问者,访问者是我们顾客,我们买东西会等活动去买,看折扣啥的,所有就增加了两个属性,折扣以及活动名字,具体实现代码如下。本例中还有一个快递公司作为访问者访问商品,定义与实现大致相同,限于篇幅,不再赘述。
typedef struct VisitorPrice
{
void (*visite)(struct VisitorPrice* obj, struct IElement_t* elem); //访问
void (*free)(struct VisitorPrice *obj); //释放内存
float discount; //打折力度
char name[32]; //活动名字
}VisitorPrice;
/**
* @brief: 访问者处理函数 实现打折计算价格
* @obj: 访问者对象,传入进去方便访问内部数据
* @elem: 被访问的元素对象指针
* @return: none
*/
static void VisitorPrice_discount(struct VisitorPrice* obj, struct IElement_t* elem)
{
if(!obj || !elem) return;
float total = (elem->info.price) * (obj->discount);
total *= elem->info.count;
printf("活动:%s 商品:%s 单价%.2f元,折扣%.2f折,数量%d件, 总价=%.2f\n", obj->name,\
elem->info.name, elem->info.price, obj->discount, elem->info.count, total);
}
/**
* @brief: 释放内存
* @obj:访问者指针
* @return:none
*/
static void VisitorPrice_free(struct VisitorPrice *obj)
{
if(obj) free(obj);
obj=NULL;
}
/**
* @brief: 打折访问者构造函数
* @discount: 折扣力度
* @name: 活动名字
* @return: 访问者对象
*/
VisitorPrice* construct_VisitorPrice(float discount, char *name)
{
VisitorPrice* obj = (VisitorPrice*)malloc(sizeof(VisitorPrice));
if(!obj) return NULL;
memcpy(obj->name, name, 32);
obj->discount = discount;
obj->visite = VisitorPrice_discount;
obj->free = VisitorPrice_free;
return obj;
}接下来我们定义实现商品,也就是被访问者(元素)。通过调用 accept 函数传入访问者抽象接口指针(可接收不同的访问者),内部调用访问者访问元素。
//元素,被访问者,商品货物
typedef struct GoodsElem_t
{
Info_t info; //货物信息
void (*accept)(struct GoodsElem_t* obj, struct IVisitor_t* visitor);//接受访问
void (*free)(struct GoodsElem_t* obj);//释放内存
struct list_head node; //链表节点
}GoodsElem_t;
/**
* @brief:接受访问
* @obj:元素对象指针
* @visitor:访问者
* @return: none
*/
static void elem_accept(struct GoodsElem_t* obj, struct IVisitor_t* visitor)
{
if(!obj || !visitor) return;
visitor->visite(visitor, (IElement_t*)obj); //接受访问者访问
}
/**
* @brief:释放内存
* @obj:元素对象指针
* @return: none
*/
static void elem_free(struct GoodsElem_t* obj)
{
if(obj) free(obj);
obj=NULL;
}
/**
* @brief:构造函数,创建元素对象
* @info: 货物信息
* @return: 对象指针
*/
GoodsElem_t* construct_goodselem(Info_t *info)
{
if(!info) return NULL;
GoodsElem_t* obj = (GoodsElem_t*)malloc(sizeof(GoodsElem_t));
if(!obj) return NULL;
memcpy(&(obj->info), info, sizeof(Info_t));//赋值
obj->accept = elem_accept;
obj->free = elem_free;
return obj;
}最后还有一个定义,管理元素的,即本例中的购物车,里面存放管理不同的商品(元素)。使用双向链表实现不同商品货物(元素)的连接管理。定义与实现如下。
//购物车 管理所有的element
typedef struct ShoppingCart_t
{
//接收访问者访问,可以访问购物车中所有的商品
void (*accept)(struct ShoppingCart_t* obj, struct IVisitor_t* visitor);
//往购物车中添加一个商品
void (*add_elem)(struct ShoppingCart_t* obj, struct IElement_t* elem);
//从购物车中删除一个商品
void (*remove_elem)(struct ShoppingCart_t* obj, struct IElement_t* elem);
//释放内存
void (*free)(struct ShoppingCart_t* obj);
//管理链表
struct list_head hlist;
}ShoppingCart_t;
//------------------------------------------
//购物车
//------------------------------------------
/**
* @brief:添加元素管理起来
* @obj:对象指针
* @elem:元素指针
* @return: none
*/
static void shopping_cart_add_elem(struct ShoppingCart_t* obj, struct IElement_t* elem)
{
if(!obj || !elem) return;
list_add_tail(&elem->node,&obj->hlist); //将element添加到链表管理
}
/**
* @brief:删除元素
* @obj:对象指针
* @elem:元素指针
* @return: none
*/
static void shopping_cart_remove_elem(struct ShoppingCart_t* obj, struct IElement_t* elem)
{
struct list_head *pos=NULL, *n=NULL;
IElement_t* node=NULL;
if(!obj || !elem) return;
list_for_each_safe(pos, n, &obj->hlist){
node = list_entry(pos, IElement_t, node);
if(node==elem){
list_del(pos);
elem->free(elem);
break;
}
}
}
/**
* @brief:内部元素对象接受访问者访问
* @obj: 对象指针
* @visitor:访问者对象指针
* @return: none
*/
static void shopping_cart_accept(struct ShoppingCart_t* obj, struct IVisitor_t* visitor)
{
struct list_head *pos=NULL;
IElement_t* elem=NULL;
if(!obj || !visitor) return;
list_for_each(pos, &obj->hlist){
elem = list_entry(pos, IElement_t, node);
elem->accept(elem, visitor);
}
}
/**
* @brief:释放对象及内部管理元素对象
* @obj:对象指针
* @return: none
*/
static void shopping_cart_free(struct ShoppingCart_t* obj)
{
struct list_head *pos=NULL, *n=NULL;
IElement_t* node=NULL;
if(!obj) return;
list_for_each_safe(pos, n, &obj->hlist){
node = list_entry(pos, IElement_t, node);
list_del(pos);
node->free(node);
}
if(obj) free(obj);
obj=NULL;
}
/**
* @brief:构造函数 创建管理元素对象
* @return: 对象指针
*/
ShoppingCart_t* construct_shoppingcart()
{
ShoppingCart_t* obj = (ShoppingCart_t*)malloc(sizeof(ShoppingCart_t));
memset(obj, 0, sizeof(ShoppingCart_t));
INIT_LIST_HEAD(&obj->hlist);
obj->accept = shopping_cart_accept;
obj->add_elem = shopping_cart_add_elem;
obj->remove_elem = shopping_cart_remove_elem;
obj->free = shopping_cart_free;
return obj;
}通过上述的定义与描述,想必大家都了解访问者模式实现原理及过程,接下来我们写代码测试实现逻辑。main 函数的实现如下。访问者 1、2 是不同活动节日访问商品,有不同的折扣。访问者 3、4 是不同的快递公司,不同的快递有不同的收费标准,计算的费用不同。购物车中的商品有玉米、小麦、大米商品,不同的访问者访问这些商品有不同的结果。
#include "visitor.h"
int main(void)
{
//计算价格的
VisitorPrice* visit1 = construct_VisitorPrice(0.85, "双十一大促销");
VisitorPrice* visit2 = construct_VisitorPrice(0.55, "元旦节清仓大甩卖");
//计算邮费的
VisitorFreight* visit3 = construct_VisitorFreight(4.2, "中通快递");
VisitorFreight* visit4 = construct_VisitorFreight(3.4, "圆通快递");
Info_t info;
info.count = 10;
info.price = 32.14;
info.weight = 1.3;
sprintf(info.name, "玉米");
GoodsElem_t* elem1 = construct_goodselem(&info);
info.count = 50;
info.weight = 3.3;
sprintf(info.name, "大米");
GoodsElem_t* elem2 = construct_goodselem(&info);
info.price = 52.02;
info.weight = 7.3;
sprintf(info.name, "小麦");
GoodsElem_t* elem3 = construct_goodselem(&info);
ShoppingCart_t* shop = construct_shoppingcart();
//往购物车添加商品
shop->add_elem(shop, (IElement_t*)elem1);
shop->add_elem(shop, (IElement_t*)elem2);
shop->add_elem(shop, (IElement_t*)elem3); //这里可以添加很多元素
//访问者1 访问购物车中所有商品
printf("访问者1: 打85折扣\n");
shop->accept(shop, (IVisitor_t*)visit1);
//访问者2
printf("\n访问者2: 打55折扣\n");
shop->accept(shop, (IVisitor_t*)visit2);
//访问者3
printf("\n访问者3: 使用中通快递邮费\n");
shop->accept(shop, (IVisitor_t*)visit3);
//访问者4
printf("\n访问者4: 使用圆通快递邮费\n");
shop->accept(shop, (IVisitor_t*)visit4);
shop->remove_elem(shop, (IElement_t*)elem3);
//访问者4
printf("\n使用圆通快递邮费,删除小麦商品\n");
shop->accept(shop, (IVisitor_t*)visit4);
shop->free(shop);
visit1->free(visit1);
visit2->free(visit2);
visit3->free(visit3);
visit4->free(visit4);
return 0;
}测试结果如下图所示:
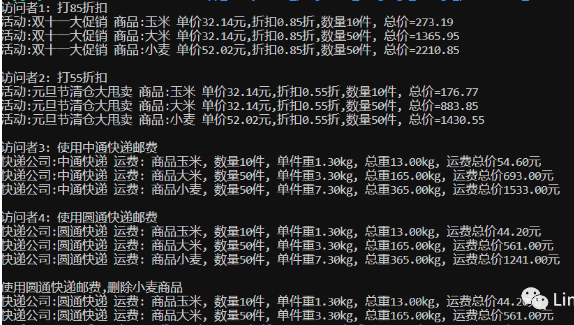
访问者设计模式适用于:1.把数据结构和作用于数据结构上的操作进行解耦合; 2.适用于数据结构比较稳定的场合。
访问者模式总结:1.访问者模式优点是增加新的操作很容易,因为增加新的操作就意味着增加一个新的访问者。2.访问者模式将有关的行为集中到一个访问者对象中。那访问者模式的缺点是是增加新的数据结构变得困难了。
虽然C语言是面向过程的编程语言,但是我们在设计程序的时候,可以考虑用面向对象的方式去设计,这样提高我们程序的“高内聚、低耦合”特性,便于维护。
版权声明:本文为「Linux 编程用C」的原创文章。
原文链接: